Vergleichsformate¶
Das generische Konzept des „Readers“, innerhalb von NCDiff, sieht vor Daten aus einer Datenquelle zu lesen und diese Daten in einer sortierten tabellarischen Form in einer CSV Datei abzulegen. Diese Datei(en) kann dann wiederum sehr einfach vom nachgelagerten Prozessen verglichen werden.
Dieser Mechanismus wird auch bei CSV, XLS und FixedWith Dateien selbst angewendet, obwohl diese Daten selbst schon in tabellarischer Form vorliegen. Grundsätzlich kann dieser Prozess aber natürlich auch auf jegliche andere Datenquelle angewendet werden.
FixedWidth¶
Textformate die fixe Feldlängen für eine tabellarische Auflistung von Werten verwenden können von NCDiff verarbeitet werden. Dazu muss in der Konfiguration die Längen der einzelnen Felder konfiguriert werden.
CSV / CSVVAR¶
Für das lesen des CSV Dateiformat wird die ausgefeilte csv Bibliothek von Python verwendet. Diese bietet
umfangreiche Konfigurationsmöglichkeiten (Trennzeichen, Escape-Zeichen,…) die auch von NCDiff als
Konfigurationsparameter zur Verfügung gestellt werden.
Der reader für CVS unterstützt nur Dateien mit einem einheitlichen Tabellenformat. Also jede Zeile hat die gleiche Spaltenanzahl. Die sind die überwiegende Mehrheit der CSV Dateien in Verwendung. Aber es gibt auch Dateien die pro Zeile unterschiedlich viele Spalten (z.B. je nach Typ des Datensatzes) ausgeben. Um diese speziellen CSV Dateien zu unterstützen gibt es den CSVVAR reader, der mit variablen Spaltenanzahl pro Zeile umgehen kann.
XLS / XLSX¶
NCDiff unterstützt sowohl das alte Microsoft Offics .xls Format (beginnend mit Excel 2.0) als auch die neuere
.xlsx Version die mit Excel 2010 eingeführt wurde.
XML¶
Sollte es sich bei einem oder beiden Teilen eines Vergleichs um XML Dateien handelt wird das hierarchische XML Format in das tabellarische CSV Format umgewandelt. Die Transformation erfolgt über einen generischen Algorithmus der sowohl mit Elementen als auch Attributen umgehen kann. Es wird davon ausgegangen das sich die grundlegenden Struktur der XML Datei wiederholt! Ein Datensatz der aus der XML Struktur extrahiert wird muss sich über einen eindeutigen Schlüssel identifizieren lassen. Solle keine sich wiederholende Struktur vorliegen kann NCDiff das XML nicht verarbeiten. Dabei wird jedes vorgefundene Element bzw. Attribut als eigenständige Spalte in der Tabelle abgebildet. Die eigentlichen Daten definieren sich aus den jeweiligen Werten der Elemente bzw. Attribute.
Eine Konvention für XML Dateien ist das Spalten in der resultierenden CSV Datei nach dem Format
[<Element-Hierachie-Ebene>|<Attribute-Index>]_<Name> angelegt werden.
Beispiel für die Namensfindung innerhalb einer XML Datei:
<TRADE>
<TRADENBR>123<TRADENBR>
<CPTY>4321</CPTY>
<CTIME isUTC=”True”>2014/04/21 12:00:00</CTIME>
<TRADE>543</TRADE>
</TRADE>
<TRADE>
<TRADENBR>654<TRADENBR>
<CPTY>928</CPTY>
<CTIME isUTC=”False”>2013/04/21 12:00:00</CTIME>
<TRADE>999</TRADE>
</TRADE>
Transformation der XML Datei in eine tabellarische Datenstruktur
[1|0]_TRADE; |
[2|0]_TRADENBR; |
[2|0]_CPTY; |
[2|0]_CTIME ; |
[2|1]_isUTC; |
[2|0]_TRADE |
; |
123 ; |
4321 ; |
2014/04/21 12:00:00; |
True ; |
543 |
; |
654 ; |
928 ; |
2013/04/21 12:00:00; |
False ; |
999 |
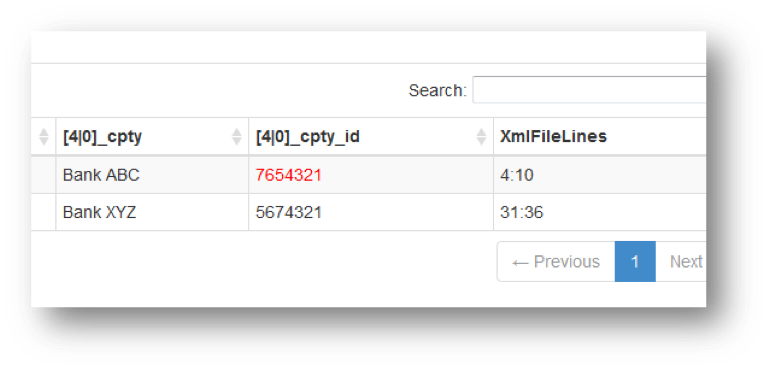
Um eine Indikation zu haben wo sich ungefähr der gefundenen Unterschied aus der originalen XML-Datei befinden, wird im „Old/New“-Data Sheet die Spalte: XmlFileLines angezeigt. In dieser Spalte sind die Nummern der Linien angegeben wo sich das auslösende XML Element befunden hat.
DIR (Dateisystem)¶
Beim Vergleich von Verzeichnisbäumen werden rekursiv folgende Informationen zu jedem Dateisystemobjekt eruiert und in einer tabellarischen Form abgelegt.
Nachfolgend eine Übersicht über die Spalten die im Zuge eine Verzeichnisabgleichs in einer CSV Datei abgelegt werden.
Als oldKeyColumns bzw. newKeyColumns bietet sich hier eine Kombination aus ABSPATH und NAME an.
Spalte |
Kurzbeschreibung |
|---|---|
NAME |
Name der Datei bzw. des Verzeichnisses (ohne Pfad, inklusive Extension) |
ABSPATH |
Absolute Pfad der Datei bzw. des Verzeichnisses innerhalb des jeweiligen Laufwerks |
RELPATH |
Relativer Pfad der Datei bzw. des Verzeichnisses zum jeweiligen Start-Verzeichnis des Vergleichs |
EXTENSION |
Erweiterung der Datei. Die letzten x Zeichen nach dem letzten Punkt in einem Dateinamen |
TYPE |
FILE, DIRECTORY, LINK |
DEPTH |
Rekursionsebene beginnend bei 1 |
SIZE |
Größe der Datei in Byte |
PERM |
Berechtigungen in POSIX Format (xrwx–x–) |
CTIME |
Datum + Zeit wann die Datei bzw. Verzeichnis erstellt wurde (ISO Format) |
ATIME |
Datum + Zeit wann die Datei bzw. Verzeichnis zum letzten mal gelesen wurde (ISO Format) |
MTIME |
Datum + Zeit wann die Datei bzw. Verzeichnis zum letzten mal verändert wurde (ISO Format) |
USER |
Besitzer der Datei bzw. des Verzeichnisses |
GROUP |
Gruppe der Datei bzw. des Verzeichnisses |
HASH |
Hashwert einer Datei (sha1) |
TAR¶
Die Daten die sich innerhalb eines (TAR) Archivs befinden gestalten sich grundsätzlich sehr ähnlich zu Daten die beim Vergleich von Dateisystemobjekten ermittelt werden können. Daher orientiert sich das Format eines TAR Abgleichs sehr stark am Format eines Verzeichnisabgleichs.
Spalte |
Kurzbeschreibung |
|---|---|
NAME |
Name der Datei bzw. des Verzeichnisses (ohne Pfad, inklusive Extension) |
PATH |
Absoluter Pfad der Datei bzw. des Verzeichnisses innerhalb des TAR Archives |
EXTENSION |
Erweiterung der Datei. Die letzten x Zeichen nach dem letzten Punkt in einem Dateinamen |
TYPE |
FILE, DIRECTORY, LINK |
DEPTH |
Rekursionsebene beginnend bei 1 |
SIZE |
Größe der Datei in Byte |
PERM |
Berechtigungen in POSIX Format (xrwx–x–) |
MTIME |
Datum + Zeit wann die Datei bzw. Verzeichnis zum letzten mal verändert wurde (ISO Format) |
USER |
Besitzer der Datei bzw. des Verzeichnisses |
GROUP |
Gruppe der Datei bzw. des Verzeichnisses |
HASH |
Hashwert einer Datei (sha1) |
Bei einer „reinen“ TAR (Tape Archive) Datei handelt es sich grundsätzlich um ein unkomprimiertes Dateiformat. TAR Dateien treten aber sehr häufig in Kombination mit einem zusätzlichen Kompressionsverfahren auf. Nachfolgend erfolgt eine Auflistung der unterstützen TAR Formate:
Format |
Kurzbeschreibung |
|---|---|
TAR |
Unkomprimierte TAR Datei |
TAR.GZ |
TAR Datei die mit GZip komprimiert wurde |
TAR.BZ2 |
TAR Datei die mit BZip2 komprimiert wurde |
Sollte das angegebene TAR Dateiformat nicht zum tatsächlichen Komprimierungsverfahren passen versucht der NCDiff TAR Reader das Komprimierungsformat selbständig herauszufinden. Dazu wendet er folgende Reihenfolge an:
Transparente Komprimierung
Komprimierung in GZip
Keine Komprimierung
Komprimierung in BZip2
Sollte die Abarbeitung dieser Reihenfolge zu keinerlei Erfolg führen wird die Verarbeitung abgebrochen.
SQL¶
Das SQL Format ermöglicht die Abfrage von Daten aus relationalen Datenbanken mittels der Structured Query Language
(SQL). Die Daten werden mittels SELECT Abfrage in Blöcken direkt über eine Datenbankverbindung abgefragt. Zur Abfrage
können Namen von Tabellen, Views oder selbst geschriebene select Abfragen verwendet werden.
Für die Spaltennamen werden automatisch die Spaltennamen aus dem Ergebnis der Abfrage verwendet, es sei denn
oldHasHeader/newHasHeader/bothHasHeader wird auf FALSE gesetzt.
Tabellen direkt auf dem Datenbankserver zu vergleichen, ohne die Daten zu übertragen zu müssen, ist nicht möglich.
Nach der Abfrage werden die Ergebnisse in Zeichenketten konvertiert und wie bei einer CSV Datei als Text sortiert. Um
zu sehen wie die ausgelesenen Daten im Sortier-Zwischenergebnis aussehen kann der Parameter keepTempFiles = TRUE
gesetzt werden.
pyodbc¶
Zum Zugriff auf Datenbanken wird ein Treiber der die Python Database API Spectification 2.0 unterstützt erwartet. Serienmäßig wird von Python lediglich die sqlite3 Datenbank unterstützt. Für den Zugriff auf andere relationale Datenbanken wird für gewöhnlich ODBC verwendet. Das Python Modul pyodbc liefert Unterstützung für den Zugriff auf ODBC via Python, muss aber gesondert installiert werden um zur Verfügung zu stehen.
Zur technischen Überprüfung der pyodbc Installation kann man folgende Befehle absetzen.
Laden des
pyodbcModuls. Hier darf keine Fehlermeldung erscheinen, falls doch dann passt das Modul nicht zur Python VersionC:\>python Python 2.6 (r26:66721, Oct 2 2008, 11:06:43) [MSC v.1500 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import pyodbcHier darf keine Fehlermeldung kommen
Überprüfung der verfügbaren ODBC Datenbank Treiber. Das Ergebnis ist eine Liste mit den Namen aller auf dem Betriebssystem installierten ODBC Treiber die von
pyodbcverwendet werden können. Falls hier Einträge fehlen, dann passt vermutlich die Bit-Zahl des ODBC Treibers mit der Bit-Zahl der Python Version nicht zusammen.C:\>python Python 2.6 (r26:66721, Oct 2 2008, 11:06:43) [MSC v.1500 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import pyodbc >>> print pyodbc.drivers() ['SQL Server', 'SQL Server Native Client 10.0'] # Das ist die ODBC Treiberliste
Windows¶
Unter Windows muss pyodbc mit der gleichen Visual Studio Version wie Python kompiliert werden, da sich das Modul ansonsten nicht laden lässt. Weiteres muss die Bit-Zahl von Python + pyodbc + ODBC Treiber übereinstimmen, denn ein 64Bit pyodbc kann keinen 32Bit ODBC Treiber verwenden und umgekehrt.
Linux – RedHat EL6.5/CentOs 6.5¶
- Um unter Linux eine Verbindung zu einem SQL Server aufzubauen werden folgende Schritte benötigt.
Vorbereitung der Umgebung (Installation u.a. von glibc, libgcc, libstdc++, krb5-libs, openssl, libuuid)
$ yum groupinstall “Development Tools”
Pyodbc Installation:
pyodbc-2.1.7-1.el6.x86_64.rpm - http://dl.fedoraproject.org/pub/epel/6/x86_64/pyodbc-2.1.7-1.el6.x86_64.rpm $ rpm -ivh pyodbc-2.1.7-1.el6.x86_64.rpm # Man könnte sich auch die Quellen herunterladen und selbst kompilieren. $ cd /var/tmp $ wget https://pyodbc.googlecode.com/files/pyodbc-3.0.7.zip $ unzip pyodbc-3.0.7.zip $ cd pyodbc-3.0.7 $ python setup.py build $ python setup.py install
Wichtig
Da wir Fehler im gcc bekommen haben, haben wir das Paket auf die schnelle einfach über RPM installiert.
Download der verschiedenen Quellen für die ODBC-Treiber
$ cd /var/tmp –msodbcsql-11.0.2270.0.tar.gz https://www.microsoft.com/en-us/download/details.aspx?id=36437 - unixODBC-2.3.0.tar.gz $ wget ftp://ftp.unixodbc.org/pub/unixODBC/unixODBC-2.3.0.tar.gz
Achtung
Im Paketmanager von CentOS ist eine neure Version des unixODBC verfügbar (yum install unixODBC). Allerdings ist diese nicht mit dem mscodbcsql kompatibel!
Installation der heruntergeladenen Quellen
$ tar xzf msodbcsql-11.0.2270.0.tar.gz $ cp unixODBC-2.3.0.tar.gz msodbcsql-11.0.2270.0/. $ cd msodbcsql-11.0.2270.0 $ ./build_dm.sh --download-url=file://unixODBC-2.3.0.tar.gz --prefix=/opt/unixODBC-2.3.0 $ ./install.sh verify $ ./install.sh install
Prüfung der erfolgreichen Installation
$ cat /etc/odbcinst.ini [ODBC Driver 11 for SQL Server] Description=Microsoft ODBC Driver 11 for SQL Server Driver=/opt/microsoft/msodbcsql/lib64/libmsodbcsql-11.0.so.2270.0 Threading=1 UsageCount=1
Wurde nun alles erfolgreich installiert und konfiguriert wurde kann der Treiber getestet werden. Zur technischen
Überprüfung der pyodbc Installation kann man folgende Befehle absetzen.
Laden des pyodbc Moduls. Hier darf keine Fehlermeldung erscheinen, falls doch dann passt das Modul nicht zur Python Version
C:\>python Python 2.6 (r26:66721, Oct 2 2008, 11:06:43) [MSC v.1500 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import pyodbcHier darf keine Fehlermeldung kommen
Neue Verbindung zur Testdatenbank von Front Arena herstellen. Zuvor sollte sichergestellt werden dass eine VPN Verbindung zum internen Netzwerk besteht.
C:\>python Python 2.6 (r26:66721, Oct 2 2008, 11:06:43) [MSC v.1500 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import pyodbc >>> con = pyodbc.connect('DRIVER={ODBC Driver 11 for SQL Server};SERVER=v022;UID=frontadmin;PWD=opus07')Hier darf kein Fehler auftreten