Appendix: XBRL¶
Im Zuge einer Anforderung via NCDiff auch XBRL (eXtensible Business Reporting Language) Dateien vergleichen zu können, wurde eine spezielle Art des XBRL Abgleiches implementiert. Gewünscht war ein Abgleich der die Daten des final ausgefüllten XBRL Formular vergleichen würden. Dies hat zur Folge das das bzw. die XBRL Formulare, einer XBRL Datei, generiert werden müssen. Die Daten aus diesen Formularen sollen danach in eine CSV Datei extrahiert werden um Sie mittels NCDiff vergleichen zu können. Da eine einzelne XBRL Datei meisten aus mehrere Formularen besteht und diese Formulare teilweise auch noch aus mehreren Blätter/Sheets bestehen kann der zu betrachtende Datenumfang erheblich sein. Ein weitere Implikation ist die technologische Gestaltung des XBRL Dateiformats selber (XML-Technology). Sie hat einen erheblichen Einfluß auf die Performance eines solchen Vergleichs. Um eine „normale“ XBRL Datei verarbeiten zu können müssen normalerweise mehr als 100 zusätzliche Definitionsdateien (nach)geladen werden. Der Speicherverbrauch ist selbst für kleine (<50KB) XBRL Dateien bei mehr als 1GB. Es war von Begin an gedacht alle XBRL „interne“ Verarbeitungslogik entweder direkt via einer Bibliothek (ähnlich eines XML-Parsers) oder einer externen Anwendung zu benutzen. Schlussendlich ist die Wahl auf eine in Python geschriebene Open-Source Appliation names Arelle gefallen. Da sich 98% der Logik für die Verarbeitung einer XBRL Datei ausserhalb des NCDiff Codes befindet wurde die XBRL Integration als eigentständige NCDfiff Extension umgesetzt.
Installation Arelle¶
Arelle wird nicht mit dem NCDiff Package mitgeliefert sondern muß hier http://arelle.org/download/ herungergeladen werden. Dabei muß berücksichtig werden das Arelle, im Gegensatz zu NCDiff betriebsystemspezifsiche Installationspackages hat. Technologisch ist das auf die Verwendung des „lxml“-Parsers zurückzuführen. Der Code dieses XML-Parser muß betriebsystemspezifisch kompiliert werden und daher existieren separate Windows, Mac-OS und Linux Pakete. Arelle selber bringt auch noch sein eigenes Python (3.3) mit. Dies wird aber nur von der Applikation selber verwenden und befindet sich in einem Unterverzeichnis der Installation selber. Das in Arelle inkludierte Python hat keinerlei Auswirkung auf das in NCDiff verwendete Python.
Nachfolgend sind die Standardverzeichnisse für die Arelle-Installation auf dem jeweiligen Betriebssytem ersichtlich. Dies hat vor allem Bedeutung da die NCDiff-XBRL Extension diese Pfade als Default-Pfade hinterlegt hat.
Windows: C:\Program Files\Arelle\arelleCmdLine.exe
MacOS: /Applications/Arelle.app/contents/MacOS/arelleCmdLine
Linux/BSD/SunOS: ./arelleCmdLine
Arelle selber besteht aus einem grafischen Benutzerinterface (GUI) und einem separaten Kommandozeileninterface. Aus Sicht von NCDiff ist nur das Kommandozeileninterface wichtig aber es sollte zumindest erwähnt sein das man sich via GUI auch eine XBRL Datei bzw. die Formulare grafisch anzeigen lassen kann.
Download und Installation XBRL Taxonomies¶
Bevor Sie mit der Installation der XBRL Taxonomies beginnen stellen Sie sicher das Sie zumindest 700MB freien Festplattenplatz zur Verfügung haben!
Ein wichtiger Bestandteil des XBRL Datenformates sind die sogenannten Taxonomies die die eigentliche Definitionen/Regeln/Spezifika innerhalb von XBRL definieren. Alle relevanten Dateien können von folgenden Hompages herungeladen werden:
Laden Sie die Taxonomies der EBA herunter:
EBA (European Banking Authority) |
EBA Taxonomies v2.2 (~85MB) |
EBA Taxonomies Homepage |
Die heruntergeladenen ZIP Datei einfach in ein Verzeichnis Ihrer Wahl entpacken.
In der EBA ZIP Datei sind nur die ZIP/7z-Dateien innerhalb des „Taxonomy/2.2.0.0“ Unterverzeichnis von Relevanz:
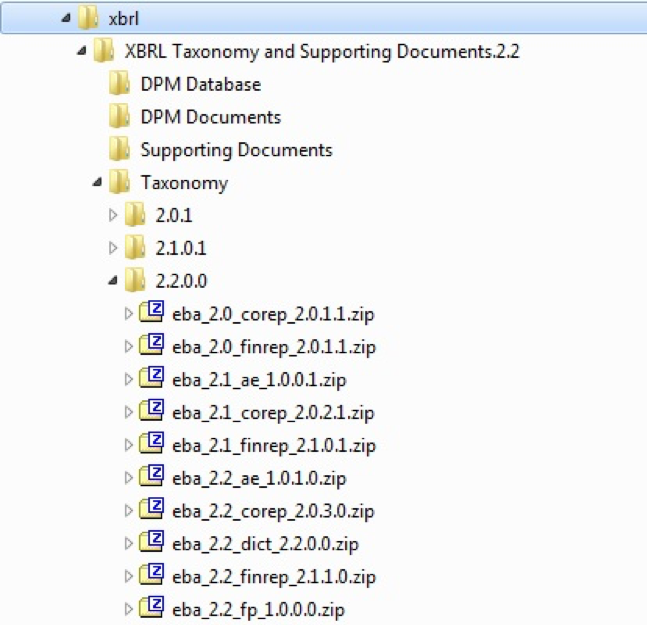
Alle die in diesem Verzeichnis enthaltenen Archive können wiederum in „genau dieses Verzeichnis“ entpackt werden.
Am Besten ist es wenn Sie mit den niedrigwertigsten Versionen (2.0) als erstes beginnen und danach die höherwertigen
(2.2) Archive darüber entpacken. Bei machen Dateien werden Sie danach gefragt werden ob Sie das Überschreiben einer
bereits existierenden Datei auch wirklich durchführen wollen, was Sie mit JA bestätigen können.
Zusätzlich sollten Sie ein neues leeres „http“ Verzeichnis innerhalb des selben Verzeichnissen anlegen. Nachfolgender Screenshot verdeutlich den Zustand des Verzeichnissen nachdem Sie alle Archive (ZIP/7z-Dateien) entpackt haben.
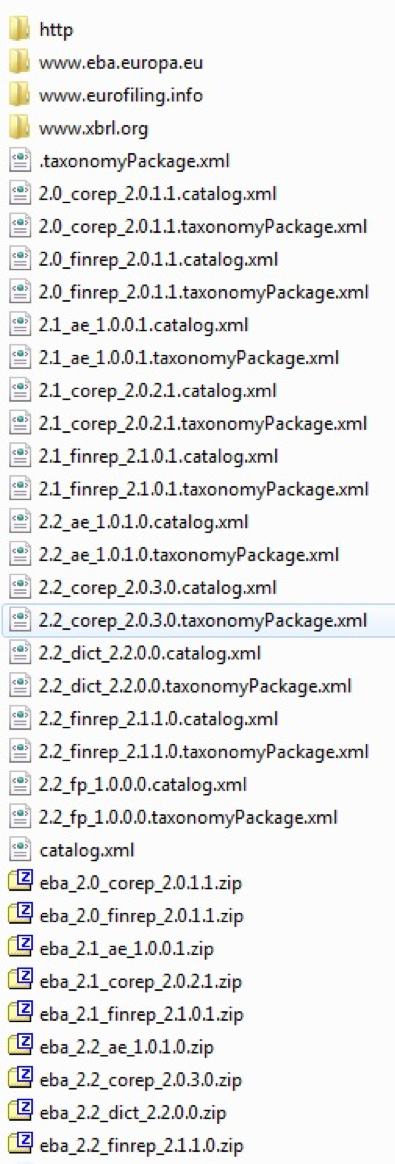
Verschieben sie alle 3 Taxonomie Verzeichnisse (www.eba.europa.eu, www.eurofiling.info, www.xbrl.org) in das „http“ Verzeichnis.
Als nächstes laden Sie die Taxonomies der Deutschen Bundesbank herunter:
Deutsche Bundesbank |
XBRL-Taxonomien gemäß ITS on reporting der EBA ab September 2014 |
DBB Taxonomies Homepage |
Legen Sie das ZIP-Archiv in genau dem selben Verzeichnis wie zuvor die EBA Taxonomies ab und entpacken Sie nun die Bundesbank Taxonomies.
Nun sollten folgender Zustand im Verzeichnis existieren:
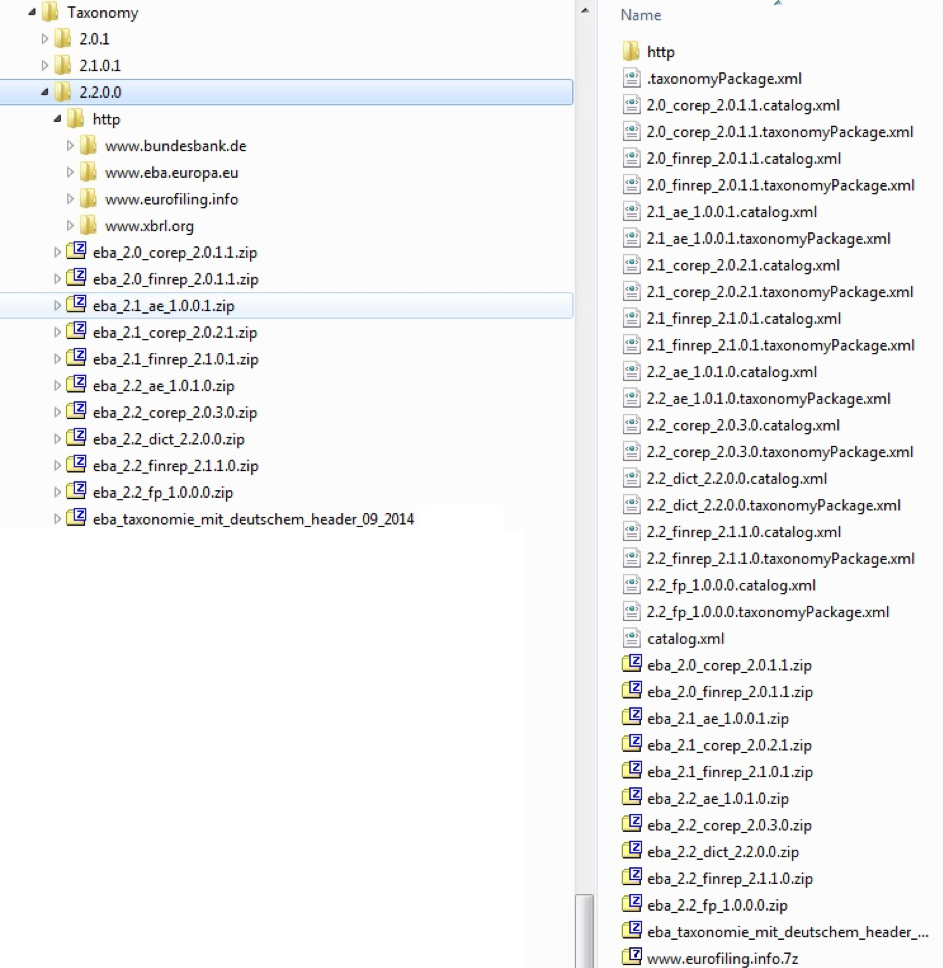
Unter dem „http“ Verzeichnis wurde noch zusätzlich das www.bundesbank.de Verzeichnis angelegt.
Um die Taxonomiekonfiguration abzuschliessen starten Sie nun das Arelle GUI. Nachdem die Applikation gestarted wurde benutzen Sie den Menüpunkt: Tools->Internet->Manage cache:
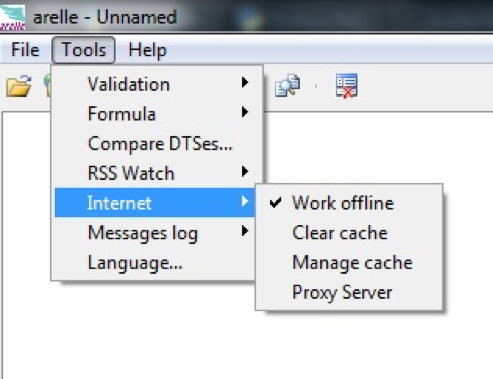
Der Menüpunkt öffnet einen neuen Windows-Explorer der normalerweise auf das Verzeichnis „C:Users<Benutzer>AppDataLocalArellecache” zeigen sollte. Verschieben Sie das komplette „http“ Verzeichnis der entpackten XBRL-Taxonomies in diese Verzeichnis. Zusätzlich können Sie noch die „Work offline“ Einstellung im GUI aktivieren. Diese verhindert das Arelle selber versucht fehlende Dateien aus dem Internet nachzuladen.
Damit ist die Installation der XBRL-Taxonomies abgeschlossen. Sie könne die ZIP/7z-Archive die im „entpack“-Verzeichnis geblieben eigentlich löschen. Es empfiehlt Sie jedoch die original heruntergeladenen ZIP-Archive aufzuheben (für zusätzlich Installation)
Der Vollständigkeit halber sollte erwähnt werden das Arelle versucht Taxonomie-Dateien die direkt oder indirekt in XBRL-Dateien referenziert werden aus dem Internet zu laden. Durch den hier beschriebenen Vorgang ist das „aus dem Internet laden“ in 99% der Fälle nicht mehr notwendig da sich bereits alle benötigten Dateien im „Cache“ befinden. Dies ist vor allem von Vorteil wenn auf dem System wo der XBRL-Vergleich gemacht werden soll keinerlei Verbindung zum Internet exisitert.
Installation Arelle „Save rendered CSV“ Plugin¶
Obwohl Arelle, in der GUI, die gerenderten XBRL-Formulare anzeigen kann existiert in der Kommandozeilenversion, der Standardinstallation, keine Möglichkeit die gerenderten Information in irgendeiner Art und Weise zu extrahieren. Daher wurde neben der NCDiff-XBRL Extension auch noch ein Arelle-Save-Rendered-CSV Plugin geschaffen.
Dieses Plugin besteht aus der Datei “arelle_save_rendered_csv.py” die im plugins Verzeichnis der Arelle Installation abgelegt werden muß:
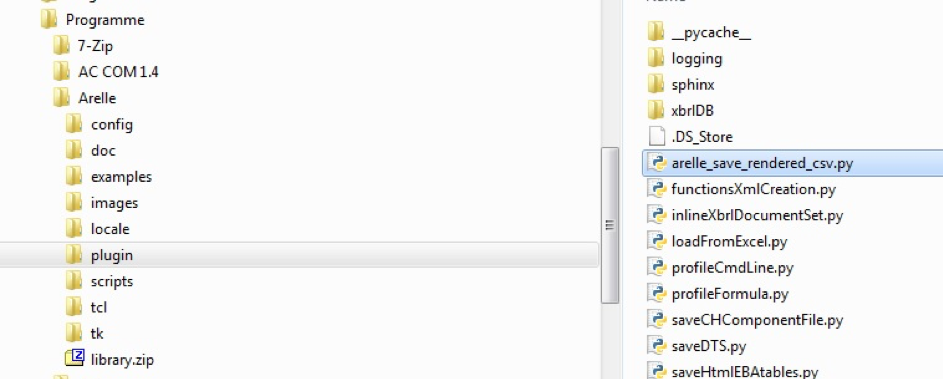
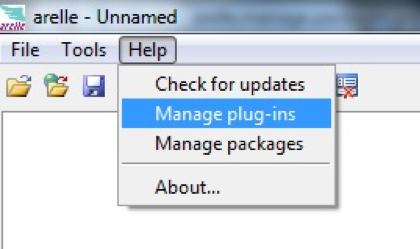
Im Arelle-GUI öffnen Sie den Menüpunkt: Help->Manage-plug-ins:
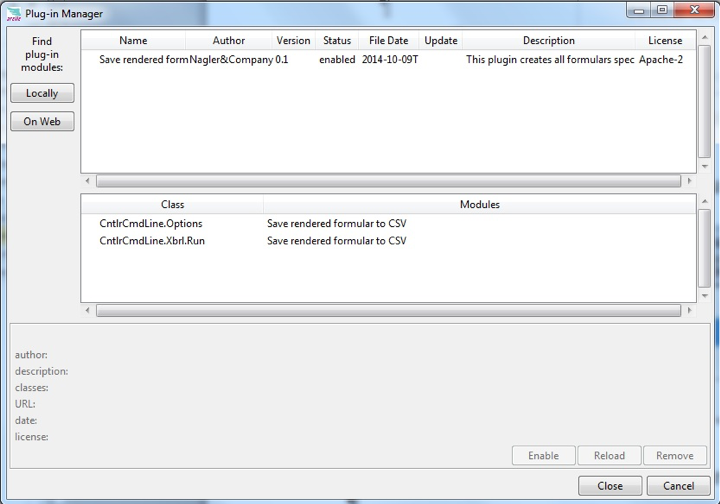
Selektieren Sie (mittels des Button „Locally“) die „arelle_save_rendered_csv.py“ Datei.
Integration XBRL-Reader Extension in NCDiff¶
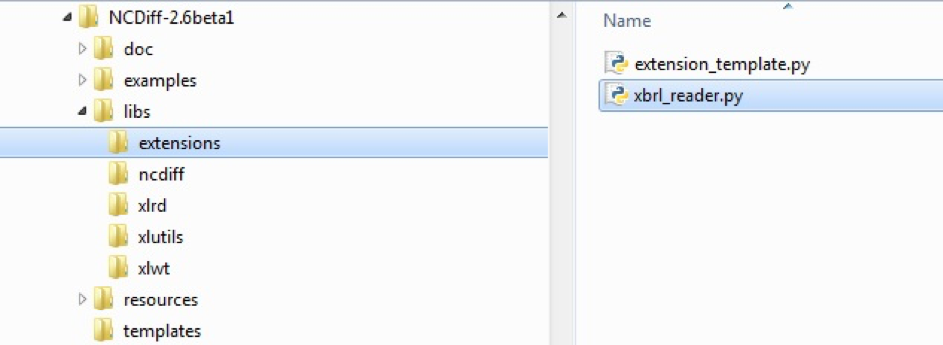
Kopieren Sie die xbrl_reader.py Datei in das libs/extensions Verzeichnis Ihrer NCDiff Installation.
Verarbeitungsprozess von XBRL Dateien in NCDiff¶
Nachfolgend ist Prozess der innerhalb von NCDiff für die Verarbeitung von XBRL-Dateien benutzt wird spezifiert.
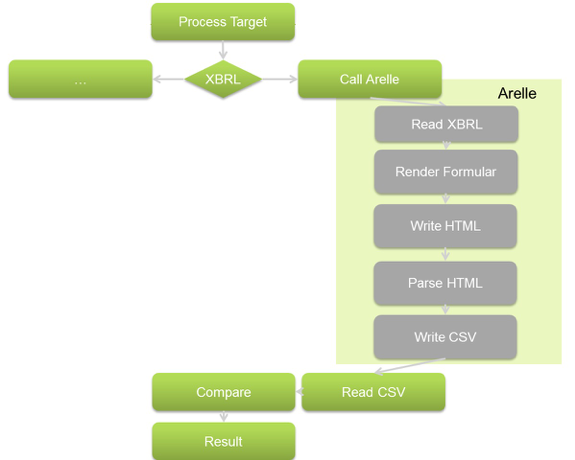
Für jedes TARGET wird überprüft ob eine XBRL-Datei betroffen ist. Sollte das der Fall sein wird via es Kommandozeilenaufrufs eine Verarbeitung via Arelle gestartet. Die übergebenen Kommanozeilenparameter definieren wo Arelle die resultierende CSV Datei ablegen soll. Von dort wird die CSV Datei wiederum von NCDiff für den Vergleich eingelesen. Die Verarbeitung innerhalb von Arelle ist auf den ersten Blick ungewöhnlich da hier eine HTML Datei geschrieben wird die wiederum benutzt wird um das finale CSV zu schreiben. Dies repräsentiert den momentan einzigen programatischen Weg an gerenderte Informationen innerhalb von Arelle zu gelangen ohne einen Großteil der XBRL-Logik neu schreiben zu müssen.
Konfigurationsbeispiele für XBRL in NCDiff¶
Nachfolgende ist eine beispielhafte Konfiguration für den Vergleich eine XBRL Datei in NCDiff ersichtlich
[GLOBAL]
resultFormats=CSV,HTML,XLS
oldDirectory=data/old/
newDirectory=data/new/
resultDirectory=results/
extensionModules=xbrl_reader
[COREP_Mini]
oldFormat=XBRL
newFormat=XBRL
oldFilePath=COREP_Mini.xbrl
newFilePath=COREP_Mini.xbrl
oldKeyColumns=1, 2, 3, 4
newKeyColumns=1, 2, 3, 4
keepTempFiles=True
extensionModules=xbrl_reader
Die globale Definition der xbrl_reader Extension signalisiert NCDiff das diese Extension für die Verarbeitung dieser Konfigurationsdatei notwendig ist. Daher sucht NCDiff im libs/extension Verzeichnis nach einer „py“ Datei die genau den spezifierten Namen trägt.
oldFormat=XBRL
Durch die Definition des Dateiformats XBRL wird signalisiert das der XBRL-Reader für die Verarbeitung innerhalb dieses Targets verwendet werden soll.
oldFilePath=COREP_Mini.xbrl
Der Verweis auf die einzulesende XBRL-Datei erfolgt wie bereits bei anderen Datenformaten (CSV, Excel, … ).
oldKeyColumns=1, 2, 3, 4
Ein weiteres wichtiges Detail ist die Definiton des Schlüssels innerhalb der resultierenden CSV Datei. Die Logik innerhalb des „Arelle-Save-Rendered-CSV“ Plugins erstellt eine Datei nach folgendem Format:
Formular |
Sheet |
Row |
Column |
Value |
|---|---|---|---|---|
C 43.00.c (LR4) |
320 |
020 |
756757000 |
|
C 43.00.c (LR4) |
320 |
040 |
622940000 |
|
C 19.00 (MKR SA SEC) |
010 |
010 |
32399000 |
|
C 19.00 (MKR SA SEC) |
010 |
020 |
6736000 |
Die Spalten „Formular, Sheet, Row und Column“ definieren den Primärschlüssel für den Vergleich.
xbrlArelleLocation="C:\\Program Files\\Arelle\\arelleCmdLine.exe"
Sollte sich die Arelle Installation nicht im Standard-Verzeichnis befinden ist es möglich den tatsächlichen Pfad global zu definieren.
xbrlArelleCommandline="-f {inputfile} --save-formular-as-csv {outputfile} --logFile=C:\\Temp\XBRL.log"
Sollte es weiters notwendig sein zusätzliche Kommandozeilen Parameter (zB: logFile) zu spezifizieren ist das auch auf globaler Ebene möglich.